農業における病害防除とドローン
皆さんはうどん粉病をご存知でしょうか。うどん粉病はあらゆる農作物にとって害となる病気です。水やアルカリに弱いので重曹水溶液の散布などで簡単に防除できますが、早期発見するためには毎日畑を見回る必要があります。これは大変です。そこで、ドローンを使って空撮し、うどん粉病があれば自動的に検出するプログラムを考えました。

減農薬の潮流が高まっているなか、農薬の使用を前提とした現行の品種では完全な無農薬栽培は比較的困難です。もし、病害虫の発生初期を画像から検知し、発生スポットに限定して農薬を散布することができれば、従来の病害虫の発生の予防措置として行われていた農薬散布の回数を減らし、減農薬を達成することができると考えられます。なお、今回のコードは、小型軽量のGPUコンピュートボードJetson TK1上で動作することを確認済みです。すなわち、ドローンがサーバーと通信せずに画像から畑の状況を認識することができます。
機体上で画像処理をすると有利な点があります。クラウドサーバーに画像処理部分を担当させる方法も考えられますが、サーバーとの通信には現状最低でも往復で500msほどの遅延が発生します。巡回速度は電気を動力源にするドローンにとって重要であり、バッテリーの容量の制限内で広い圃場を効率よく管理するために速度は速いほど有利です。燃料を動力源にするドローンもありますが、こちらも騒音の問題があり、飛行は短時間であることが望まれています。

その点で、クラウド型の場合、ドローンで圃場の上を飛行し撮影した画像をサーバーに転送、応答を待ってから農薬の散布の有無が決定されるので、どうしても進行速度に制限がかかってしまいます。具体的には、1m進行するために1枚の画像の処理が必要だと仮定すると、500msの通信遅延の下ではサーバーでの処理時間が0秒であったとしても、1秒間に2mしか進めないことになります。現実的にはサーバーでの処理時間が0秒ではないため、1秒間に1m程度が限界になると思われます。
そこで、画像処理・並列処理に特化したGPUを機体に搭載することで画像認識をサーバーとの通信を介さずに高速に行うと、進行速度の向上を図ることができます。ネットワーク遅延がないため、Jetson TK1実機上での性能として、画像1枚の処理あたり、1msで処理を完了できました。ゆえに、このシステムでは従来より高速に圃場を巡回し、農薬を散布することができます。
病気を人工知能で見つける
データセットの概要
今回のコードでは機械学習ライブラリChainerを使用しています。Pythonのインストールはこちらに示してあります。ChainerのインストールはCPU版はこちら、GPU版はこちらでインストール方法を解説しています。
機械学習により、うどん粉病の発生している葉を認識します。かぼちゃの葉でデータセットを作りました。
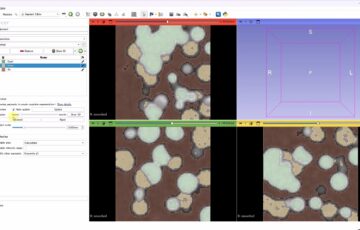
画像の例としては次のようなものになります。1つ目が正常、2つ目がうどん粉病にかかった葉です。うどん粉病にかかると、葉に白い斑点ができるようになります。


最終的に次のように分類ができます。ansが答え、recogが機械学習による推定結果、これらが一致していれば青色で、間違っていれば赤色で文字が表示されます。非常に高い正答率が得られています。

ディレクトリの配置は次のようなものを想定しています。scriptディレクトリの中にpythonのソースコードを置くか、この場所をワーキングディレクトリにしてください。
├── script │ ├── test.txt │ └── train.txt └── train_data ├── 0 │ ├── 0_0_0.jpg │ ├── 0_0_128.jpg │ ├── 0_0_32.jpg : : : │ ├── 5_96_192.jpg │ └── 5_96_96.jpg └── 1 ├── 0_0_0.jpg ├── 0_0_128.jpg ├── 0_0_160.jpg : : : ├── 5_96_32.jpg ├── 5_96_64.jpg └── 5_96_96.jpg
まずは、画像のサイズの確認です。
import cv2
img = cv2.imread(r"../train_data/0/0_0_0.jpg", 0)
print img.shape
imsize = img.shape[0]
GPU=1
CHANNEL=1
(64, 64)
64*64の正方形の画像です。今回のプログラムはGPUの使用・不使用を簡単に切り替えられるようにしています。使用する場合にはGPU=1、不使用の場合にはGPU=0とします。CHANNELは画像をRGBとして読み込むか、グレースケールで読み込むかを決めるパラメータです。グレースケールなら1、RGBカラーなら3を指定します。今回は正常な葉とうどん粉病の葉で色味がやや違うデータセットとなってしまっているので、グレースケールで進めます。
学習モデル
次に学習モデルを定義します。畳み込み層Convolution2Dと、正規化層BatchNormalizationを交互に組み合わせ、最後に2層のニューラルネットワークを使ったモデルになります。
import numpy as np
import chainer
import chainer.functions as F
import chainer.links as L
from chainer import optimizers, serializers, cuda
import cv2
import time
if GPU:
from chainer import cuda
xp = cuda.cupy
else:
xp = np
class UdonkoModel(chainer.Chain):
def __init__(self):
super(UdonkoModel, self).__init__(
conv1=L.Convolution2D(CHANNEL, 16, 5),
bn1 = L.BatchNormalization(16),
conv2=L.Convolution2D(16, 16, 5),
bn2 = L.BatchNormalization(16),
conv3=L.Convolution2D(16, 16, 5),
l1=L.Linear(64, 64),
l2=L.Linear(64, 2),
)
def __call__(self, x, t, train):
h = F.max_pooling_2d(F.relu(self.conv1(x)), 3)
h = self.bn1(h)
h = F.max_pooling_2d(F.relu(self.conv2(h)), 3)
h = self.bn2(h)
h = F.relu(self.conv3(h))
h = F.dropout(F.relu(self.l1(h)), train=train)
h = F.dropout(F.relu(self.l2(h)), train=train)
if train:
return F.softmax_cross_entropy(h, t), F.accuracy(h, t)
else:
return h, F.accuracy(h, t)
if GPU:
gpu_device = 0
cuda.get_device(gpu_device).use()
model = UdonkoModel()
if GPU:
model.to_gpu(gpu_device)
optimizer = optimizers.Adam()
optimizer.setup(model)
モデルのトレーニングと評価
いよいよ、学習です。それぞれtrain.txtと、valid.txtに学習用データと検証用データの画像のパスが記述されています。最終的に97%の検証用画像(学習に用いていない画像)を正しく判定できています。
import time
if CHANNEL == 3:
ax=(0,1)
imreadType=cv2.IMREAD_COLOR
else:
ax=0
imreadType=cv2.IMREAD_GRAYSCALE
# train list
x_train = []
y_train = []
for line in open(r"train.txt"):
pair = line.strip().split()
img = cv2.imread(pair[0], imreadType)
img = np.array(((img.astype(np.float32) - np.mean(img,axis=ax))/np.std(img,axis=ax)*16+64)/255.0,dtype=np.float32)
x_train.append(img)
y_train.append(int(pair[1]))
# test list
x_test = []
y_test = []
for line in open(r"test.txt"):
pair = line.strip().split()
img = cv2.imread(pair[0], imreadType)
img = np.array(((img.astype(np.float32) - np.mean(img,axis=ax))/np.std(img,axis=ax)*16+64)/255.0,dtype=np.float32)
x_test.append(img)
y_test.append(int(pair[1]))
x_train = xp.array(x_train).reshape(len(x_train), CHANNEL, imsize, imsize)
x_test = xp.array(x_test).reshape( len(x_test) , CHANNEL, imsize, imsize)
y_train = xp.array(y_train, dtype = xp.int32)
y_test = xp.array(y_test , dtype = xp.int32)
train_data, test_data, train_label, test_label = x_train, x_test, y_train, y_test
print train_data.shape
print "training start"
if 1:
serializers.load_npz("model_1000-ch"+str(CHANNEL), model)
serializers.load_npz("state_1000-ch"+str(CHANNEL), optimizer)
for epoch in range(1000):
model.zerograds()
loss, acc = model(train_data, train_label, train=True)
loss.backward()
optimizer.update()
if epoch%20==0:
print "epoch:",epoch,"\tacc:", acc.data
starttime = time.time()
r, acc = model(test_data, test_label, train=False)
endtime = time.time()
interval = (endtime - starttime)/len(x_test)
print(str(interval) + "sec/picture")
print "acc test ", r.data, acc.data
serializers.save_npz("model_{}".format(1000)+"-ch"+str(CHANNEL), model)
serializers.save_npz("state_{}".format(1000)+"-ch"+str(CHANNEL), optimizer)
print "complete"
(146, 1, 64, 64) training start epoch: 0 acc: 0.726027369499 epoch: 20 acc: 0.712328791618 epoch: 40 acc: 0.705479443073 epoch: 60 acc: 0.739726006985 : : : epoch: 920 acc: 0.780821919441 epoch: 940 acc: 0.712328791618 epoch: 960 acc: 0.74657535553 epoch: 980 acc: 0.739726006985 0.00013929605484sec/picture acc test [[ 11.51809406 0. ] [ 5.1250968 0. ] [ 7.28319311 0. ] [ 7.71939278 0. ] [ 11.13335514 0. ] [ 8.04593849 0. ] : : [ 0. 7.20745754] [ 0. 3.47049403] [ 0. 6.05735731] [ 0. 4.02106762] [ 0. 4.19542599]] 0.977272748947 complete
簡単な可視化
どの画像が、どのように判定されているかを可視化するコードも示しておきます。
import matplotlib.pyplot as plt
%matplotlib inline
def draw_digit3(data, n, ans, recog):
plt.subplot(7, 6, n)
Z = data[::-1,:] # flip vertical
plt.xlim(0,imsize-1)
plt.ylim(0,imsize-1)
plt.imshow(Z)
if ans==recog:
plt.title("ans=%d, recog=%d"%(ans,recog), size=8, color="c")
else:
plt.title("ans=%d, recog=%d"%(ans,recog), size=8, color="r")
plt.gray()
plt.tick_params(labelbottom="off")
plt.tick_params(labelleft="off")
plt.figure(figsize=(10,10))
result = np.argmax(r.data, axis=1)
for i,line in enumerate(open(r"test.txt")):
if i>41:
continue
pair = line.strip().split()
img = cv2.imread(pair[0], cv2.IMREAD_COLOR)
img = np.array(((img.astype(np.float32) - np.mean(img,axis=ax))/np.std(img,axis=ax)*32+128)/255.0,dtype=np.float32)
draw_digit3(cv2.cvtColor(img, cv2.COLOR_BGR2RGB), i+1, int(pair[1]), result[i])
このコードで冒頭の分類画像が表示できます。
おわりに
機械学習の応用を考えると夢が膨らみますね。これからも色々な応用を考えていきたいです。