1説明変数の線形回帰
xとyの関係が定数a、bを用いて、y=ax+bというように表現されると予想できるとき、線形回帰を行います。このページで使用するデータとして、まず、以下の仮想的なデータを代入します。散布図を書くと、どうやらxとyの間には直線の関係がありそうです。
x <- c(2,2,3,4,5,6,6,6,6,7,8,9)
y <- c(8,7,7,5,8,5,4,3,4,3,2,1)
xy <- data.frame(X=x,Y=y)
plot(xy)

lm関数を使って単回帰を行う
以下のようにコマンドを打つことにより回帰を行うことができます。
xy.lm <- lm(Y~X,data=xy)
結果の確認
summary関数で回帰の結果の概要を知ることができます。
summary(xy.lm)
以下のように出力されます。
Call:
lm(formula = Y ~ X, data = xy)
Residuals:
Min 1Q Median 3Q Max
-1.12805 -0.46189 -0.16159 0.08994 2.93902
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 9.7256 0.8746 11.120 5.96e-07 ***
X -0.9329 0.1522 -6.128 0.000112 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1.126 on 10 degrees of freedom
Multiple R-squared: 0.7897, Adjusted R-squared: 0.7687
F-statistic: 37.55 on 1 and 10 DF, p-value: 0.0001115
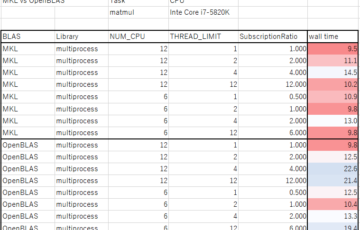
Residualsは残差についての要約で、最小値が-1.12805、最大値が2.93902とわかります。Coefficientsは回帰直線の係数についての項目で、y = -0.9329 x + 9.7256 の式が得られています。標準誤差(Std.Error)、t値、有意確率(Pr)が順に続いており、今回の例では有意確率が非常に小さく、***という印がついているため、係数は0.1%有意水準を満たしているとわかります。その下に続くもののうち重要なのが、Multiple R-squared: 0.7897 と Adjusted R-squared: 0.7687 のところで、それぞれ決定係数、自由度調節済み決定係数と言い、被説明変数(y)の変化のうち、推定式で説明できた割合のことを指します。自由度調節済み決定係数は今回は説明変数が1つであるため無視しても構いませんが、重回帰分析などで説明変数が増えるときには重要です。
信頼区間と予測区間
predict関数で回帰直線の信頼区間と予測区間を計算できます。interval引数に”confidence”を指定すれば信頼区間、”prediction”を指定すれば予測区間を計算します。以下の例ではlevel引数に0.95を指定しているため95%信頼区間・予測区間をプロットしますが、プロットの対象が多いためグラフをまとめて描画できるmatplot関数を使用しています。回帰直線は赤色、信頼区間は青色実線、予測区間は青色点線で描画されます。なお、95%信頼区間とは、全く同じやり方で測定・解析を100回繰り返したら、100回のうち95回の確率で回帰直線が通る範囲です。95%予測区間は、新しく別のデータが得られたときに、その区間に95%の確率で含まれるというような範囲です。
newdata <- data.frame(X=seq(2,9,0.1)) #ベクトルとして2以上9以下の0.1刻みの値を作る
xy.con <- predict(xy.lm,newdata,interval="confidence",level=0.95) #信頼区間
xy.pre <- predict(xy.lm,newdata,interval="prediction",level=0.95) #予測区間
xy.con <- as.data.frame(xy.con) #データフレーム形式に変換
xy.pre <- as.data.frame(xy.pre)
plot(xy,xlim=c(2,9),ylim=c(0,10))
par(new=TRUE) #前のグラフと重ね合わせるための処理
matplot( #グラフをまとめて描画する関数
x=newdata$X,
y=cbind(xy.con$fit, xy.con$upr, xy.con$lwr, xy.pre$upr, xy.pre$lwr),
xlim=c(2,9),ylim=c(0,10),
axes=F, ylab="", xlab="",
type="l",
lwd=c(1.5, 1, 1, 1, 1),
lty=c(1, 1, 1, 2, 2),
col=c("red", "blue", "blue", "blue", "blue")
)